
9.05 Analyzing experimental data
Introduction
This lesson uses simulation in combination with our previous understanding of normal distributions and margin of error, from lesson 9.03 Normal distributions and lesson 9.04 Margin of error , to analyze data from experiments, as well as the strength of claims made using such data.
Analyzing experimental data
Commonly in an experiment, you are comparing two groups, one of which is being given a treatment and the other of which is the control group without any treatment. When we observe differences between the control and treatment group, we require a method to determine if the variability is due to the treatment or due to chance and natural variation.
We can use simulation to shuffle the outcomes into two randomly assigned groups to help us decide if differences between parameters are significant.
Exploration
Two sets of numbers are shown below. The two groups have a different mean. Can we conclude that the numbers were selected from different populations?
Use the applet to explore the difference in the mean of the two groups if the numbers were randomly shuffled and then split into two groups.
Create a distribution of 100 randomizations and answer the following questions:
Estimate the mean of the sample distribution.
What was the lowest and highest difference generated in the randomizations?
What percentage of differences were of size 1.2 or greater?
Does the original difference of 1.2 in the means of the two groups lead you to believe the groups were selected from different populations? Justify your answer.
Does the sampling distribution appear to be approximately normally distributed? Explain your answer.
For two sets of experimental data, a control group and treatment group, with an observed difference in their means, we can create a randomization distribution to determine if the observed difference is significant enough to conclude the treatment has an effect.
We can do this by:
Grouping together all of the data, then randomly reassigning the data into different groups
Finding the difference between the means of these new groups
Repeat the process several times to create a distribution of the differences between the means
Compare the difference in means found in the experiment to this randomization distribution to determine whether or not it likely occurred by chance
We can test one or both tails of the distribution to determine whether an observed difference in the groups is significant. In a two-tailed test, we test for the possibility of positive or negative differences equal to or larger in size than the observed difference. In a one tail test, we only test in one direction. Consider the following when deciding to use a one or two-tailed test:
Testing both tails is appropriate if you want to determine if there is any difference between the groups you are comparing but are not concerned with the direction of the difference. For example, if you want to test if Group A scored differently than Group B but don't care which group scored higher.
A one-tailed test is appropriate if you only want to determine if there is a difference between groups in a specific direction. For example, if you are only interested in determining if Group A scored higher than Group B, and you are not interested in possibility of Group A scoring lower than Group B, then you may want to use a one-tailed test.
Examples
Example 1
A research team wants to test the effectiveness of a new medication for diabetes over a current medication. Twenty patients are split into two groups, with 10 receiving the new medication and 10 remaining on the current medication.
The patients are tested after a period of using the medication. The results below reflect how well the blood sugars are being controlled. The lower the number is, the better.
| Control | 8.2 | 9.1 | 7.2 | 6.8 | 8.4 | 6.5 | 8.0 | 7.4 | 10.2 | 6.7 |
|---|---|---|---|---|---|---|---|---|---|---|
| Treatment | 9.2 | 7.4 | 6.4 | 7.7 | 7.0 | 8.0 | 7.2 | 6.7 | 7.9 | 6.3 |
Determine the observed difference between the means of the two groups.
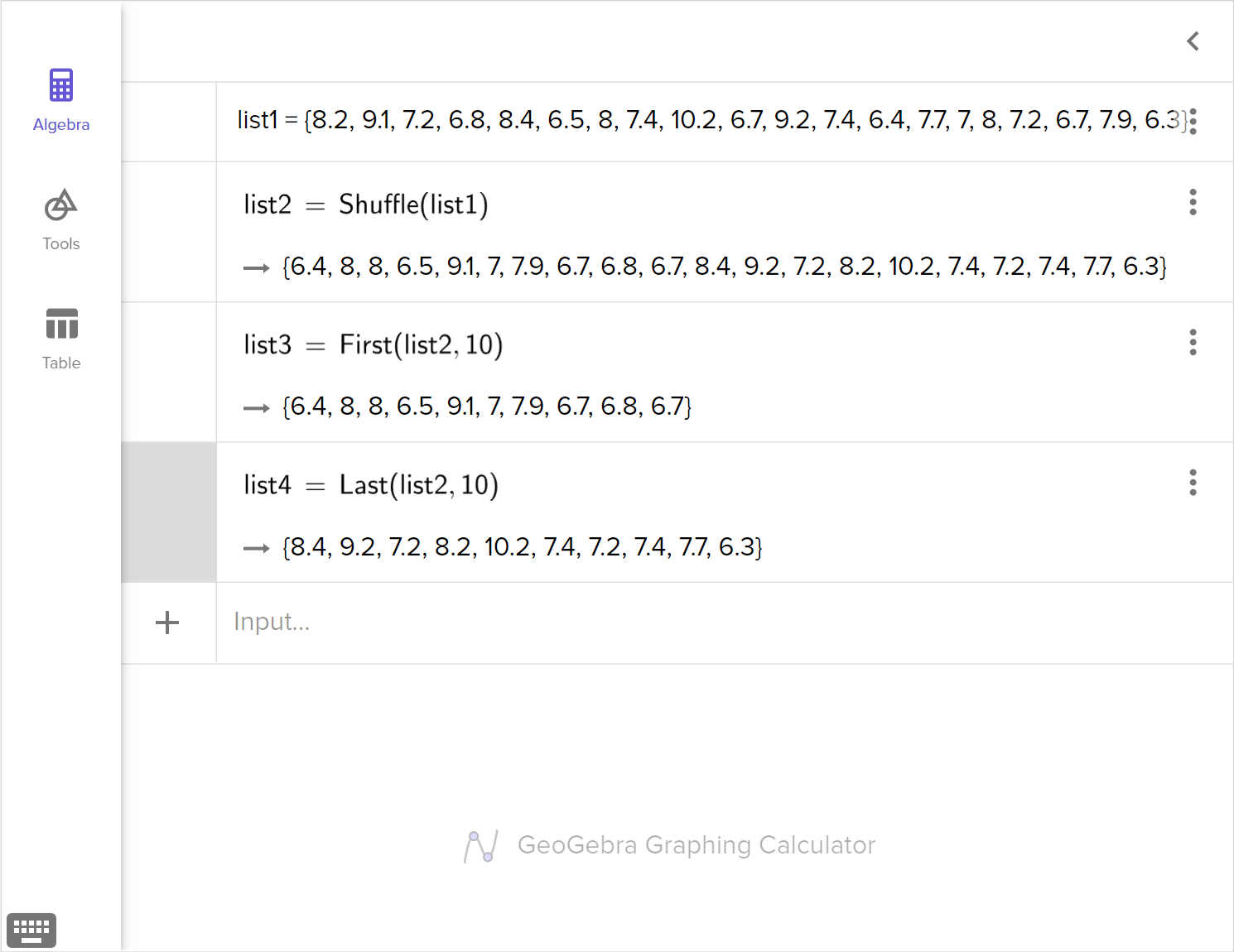
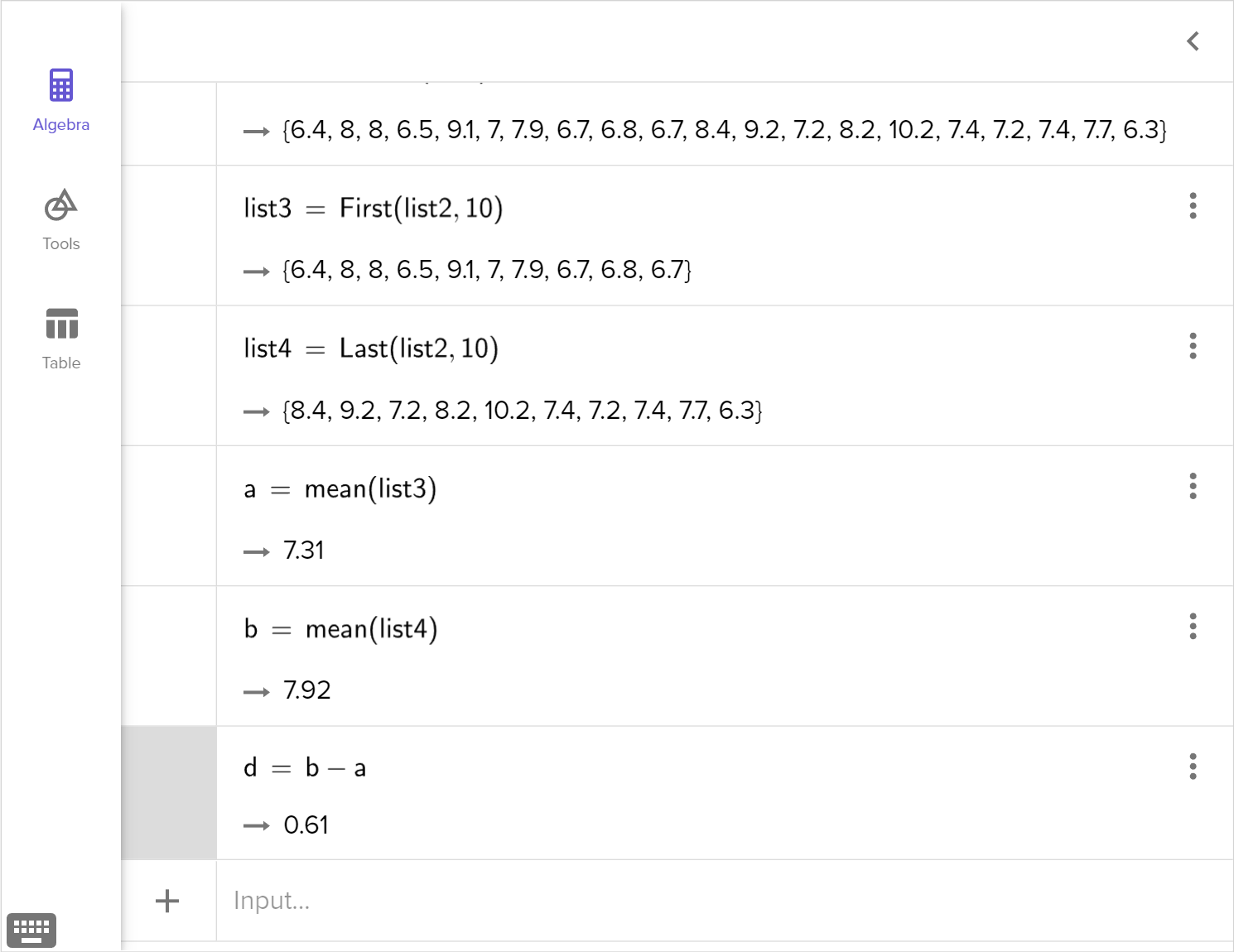
Randomly assign the data to two new groups and determine the difference of the means for this randomization.
A sampling distribution for the difference of means using 200 random samples is shown below.

Estimate the percentage of differences that were at or below the observed difference.

Explain whether or not the trial showed conclusively that the new medication is more effective than the current medication in improving how well the blood sugars were being controlled.
Example 2
A farmer runs a trial of a new diet for his chickens to test if it has any effect on the weight of the eggs produced. The farmer creates two small groups of hens, giving one group the new diet while keeping a control group on the current diet. He collects and weighs 20 eggs from each group. The eggs produced on the new diet had a mean weight of 59.8 \text{ g}, while the eggs on the original diet had a mean weight of 57.1 g.
The groups of chickens were then randomized and the difference in the mean weight recorded. The following distribution shows the results of 180 randomizations.

Use the sampling distribution to determine whether or not the new diet makes a significant difference in increasing the weight of the eggs produced by the hens.

From the trial, determine if it would be reasonable to claim that the new diet increases the average weight of eggs by at least 2 grams, given that the sample of 20 eggs from hens on the new diet had a mean of 59.8g and a standard deviation of 3.6g and the eggs from hens on the original diet have a confirmed population mean weight of 57.1g.
Example 3
Otis works in a game store and claims that customers are more likely to be male. To support his claim, he records the gender of every tenth customer in the store over a week. At the end of the week he has recorded 135 males and 115 females enter the store.
Design a simulation to test whether or not the difference in the number of customers is significant enough to support Otis' claim.
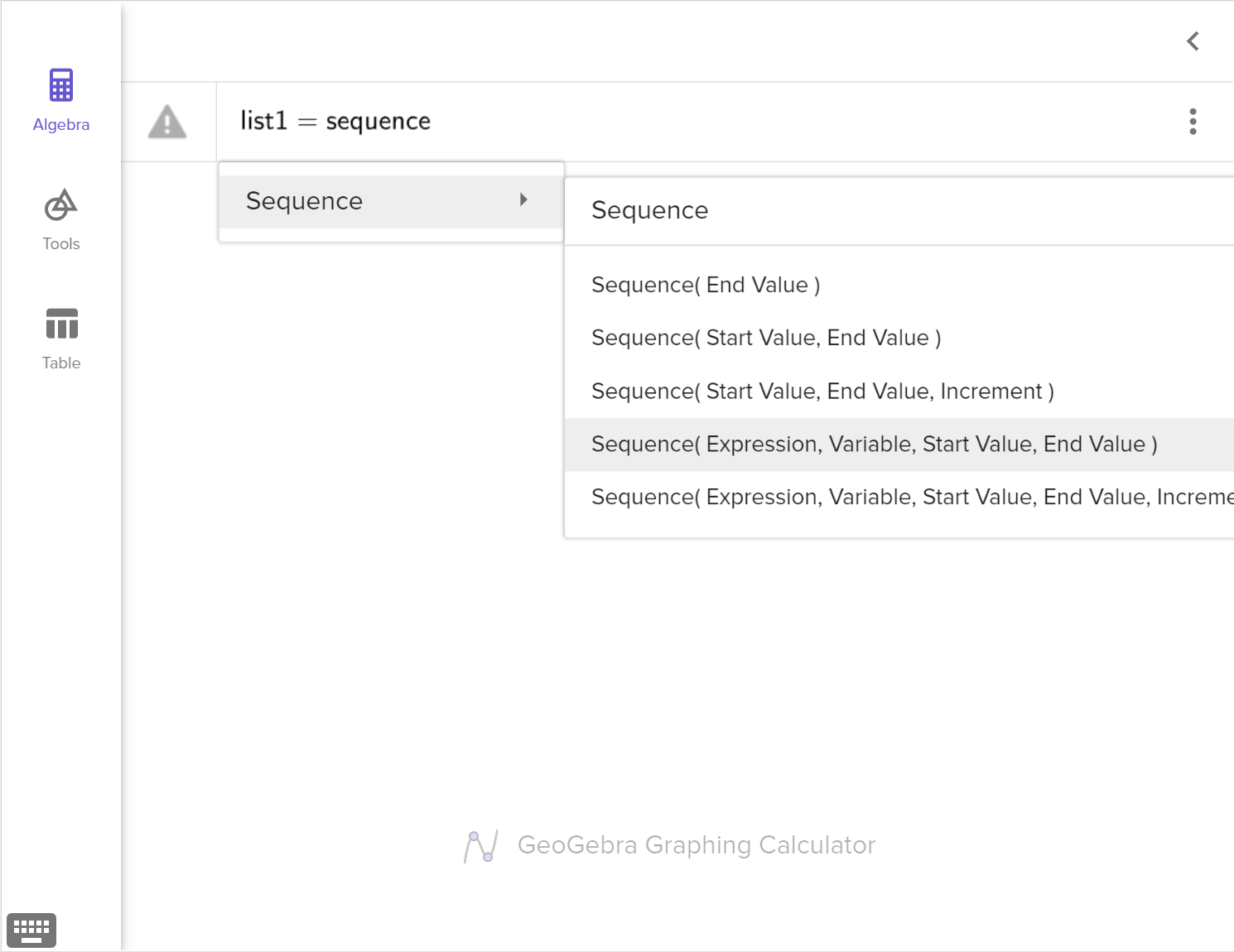
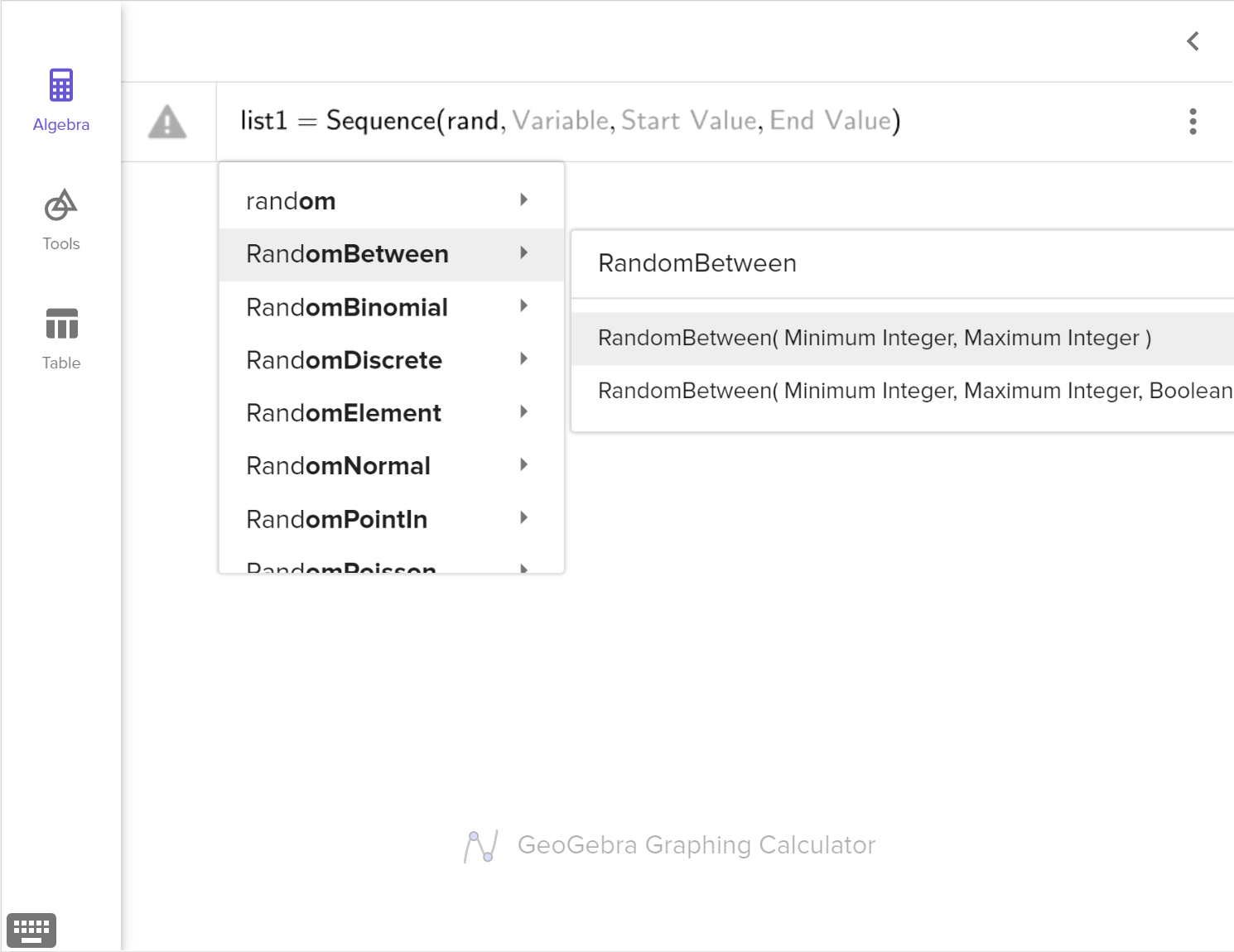
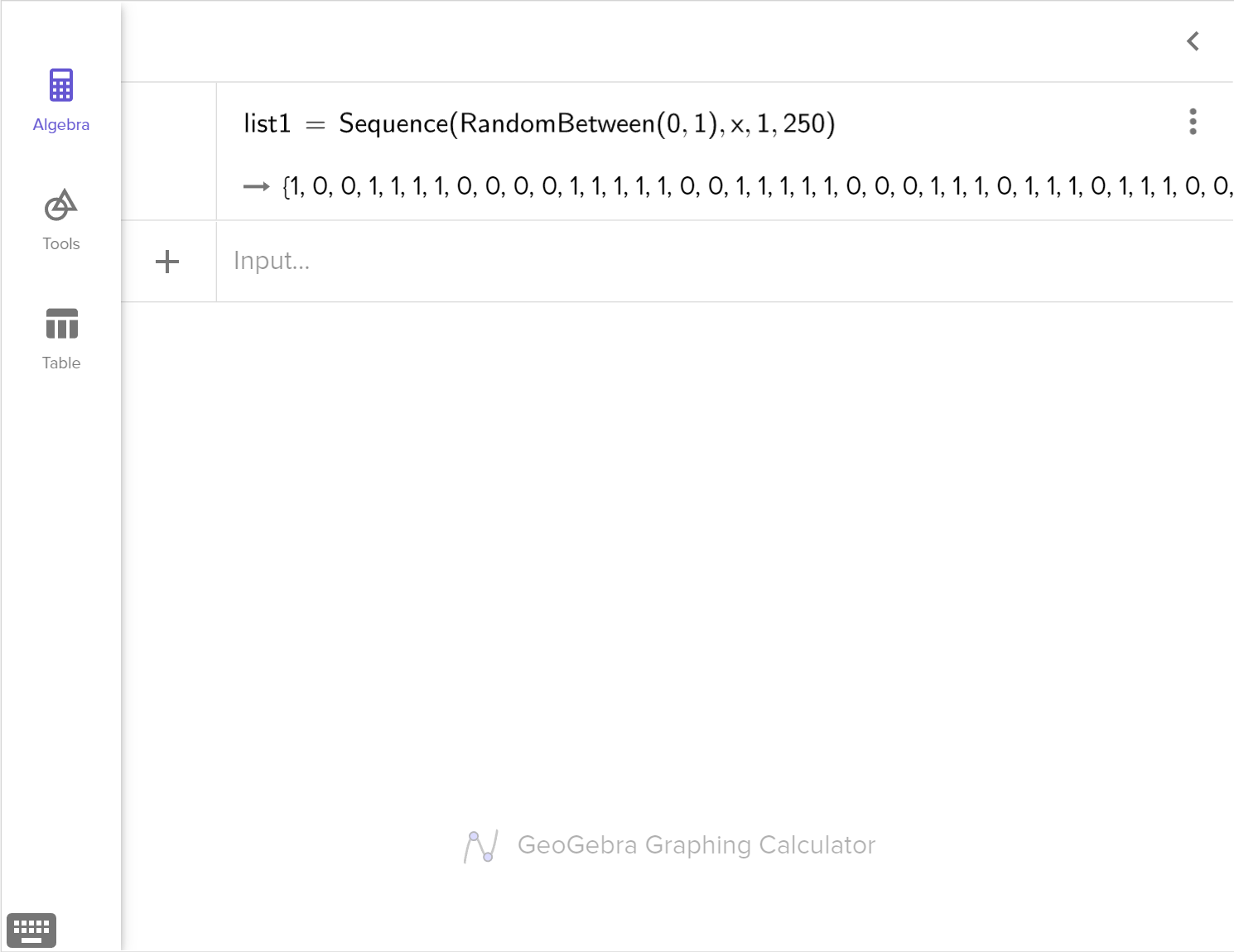
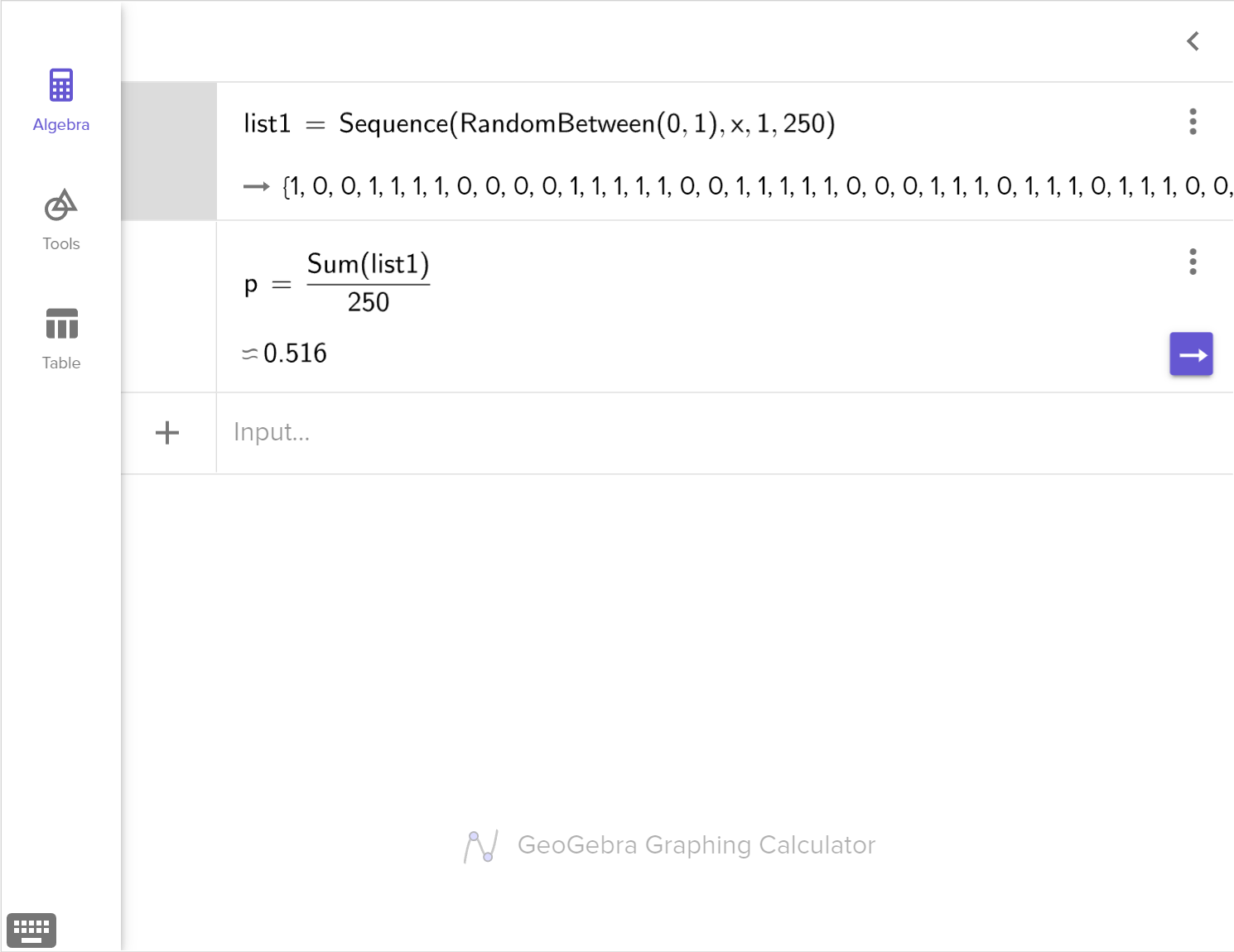
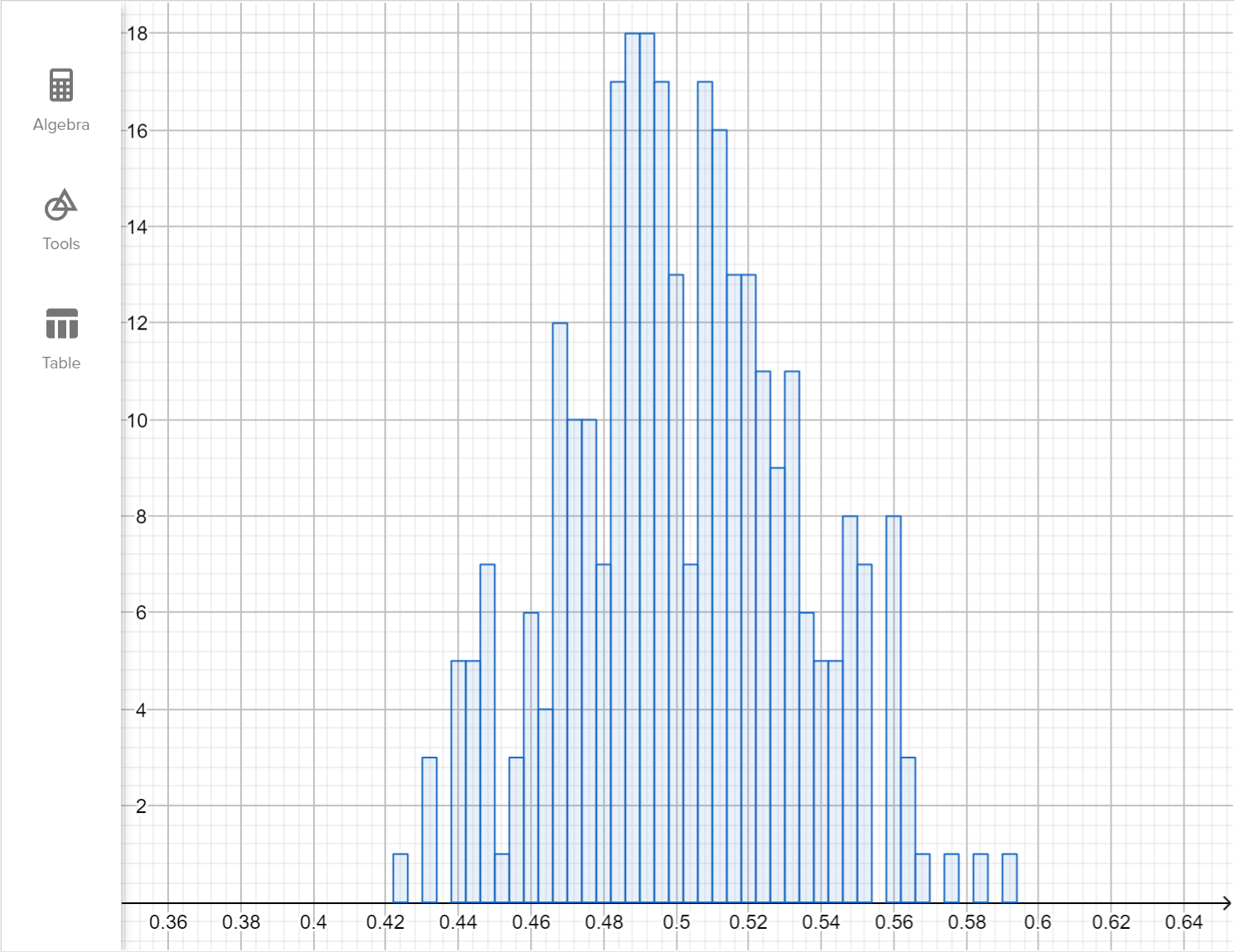
In an experiment, we often compare two groups. One is being given a treatment and the other is the control group without any treatment. We may observe statistical differences between the two groups. We need to decide if the differences are likely due to the treatment or to natural variation.
We can use simulation to shuffle the observed outcomes into two randomly assigned groups for a large number of trials. Then, we analyze the randomized sample distribution to determine how likely the observed statistical difference would occur due to natural variation.
This same randomization process can also be used in observational or survey studies, when we need to determine the likelihood that differences between two groups are due to chance, or if there may be some correlational relationship.