
Univariate versus bivariate statistics
In Unit 2 we studied statistics with univariate data. 'Uni' means one (think unicycle) so if we want to observe and analyse changes in a single variable then this is univariate statistics. For example, comparing two student's test results by comparing the mean and standard deviation of each set is working with a single variable (test results) so it is univariate.
In Unit 3 our focus will be statistics with bivariate data. 'Bi' means two (think bicycle) so if we are interested in comparing or finding an association between two sets of different variables then this is bivariate statistics. For example, looking at the association between litres of soft drink consumed per week and BMI for a set of people is working with bivariate data as there are two variables (litres and BMI).
Types of data
In statistics, a 'variable' refers to a characteristic of data that is measurable or observable. A variable could be something like temperature, mass, height, make of car, type of animal or goals scored.
Data variables can be defined as either numerical or categorical.
- Numerical data is where each data point is represented by a number. Examples include: number of items sold each month, daily temperatures, heights of people, and ages of a population. The data can be further defined as either discrete (associated with counting) or continuous (associated with measuring). Numerical data is also known as quantitative data.
- Categorical data is where each data point is represented by a word or label. Examples include: brand names, types of animals, favourite colours, and names of countries. The data can be further defined as either ordinal (it can be ordered) or nominal (un-ordered). Categorical data is also known as qualitative data.

Discrete numerical data
Discrete numerical data involve data points that are distinct and separate from each other. There is a definite 'gap' separating one data point from the next. Discrete data usually, but not always, consists of whole numbers, and is often collected by some form of counting.
Examples of discrete data: number of goals scored per match ($1$1, $3$3, $0$0, $5$5, etc) , number of children per family ($0$0, $1$1, $2$2, $3$3, etc), number of products sold each day ($123$123, $145$145, $231$231, etc)
Continuous numerical data
Continuous numerical data involves data points that can occur anywhere along a continuum. Any value is possible within a range of values. Continuous data often involves the use of decimal numbers, and is often collected using some form of measurement.
Examples of continuous data: height of trees in metres ($12.357$12.357, $14.022$14.022, $13.454$13.454, etc), times taken to run ten km in minutes ($55.34$55.34, $58.45$58.45, $61.29$61.29, etc), daily temperature in degrees C ($31.2$31.2, $29.4$29.4, $30.4$30.4, etc)
Ordinal categorical data
The word 'ordinal' means 'ordered'. Ordinal categorical data involves data points, consisting of words or labels, that can be ordered or ranked in some way.
Examples of ordinal data: product rating on a survey (good, satisfactory, excellent), Level of achievement (high distinction, distinction, credit, pass, fail)
Nominal categorical data
The word 'nominal' means 'name'. Nominal categorical data consists of words or labels, that name individual data points.
Example of nominal data: Nationalities in a team (German, Austrian, Italian, Spanish, etc), eye colour (grey, blue, brown, green, etc)
Practice questions
question 1
Classify this data into its correct category:
Weights of dogs
Categorical Nominal
ACategorical Ordinal
BNumerical Discrete
CNumerical Continuous
D
Question 2
A scientist collects data on iron levels in soil and growth of a type of weed in order to investigate the relationship between them.
Is this an example of univariate data or bivariate data?
Univariate data
ABivariate data
B
Analysing univariate data: measures of central tendency
Measures of central tendency, or measures of location, refer to statistical quantities that tell us where the middle of the scores is (the average). There are 3 of these measures: mean, median and mode. They can all be referred to as "averages" of the data set.
Mean
The mean is what we typically consider to be the average of all the scores.
If the data is given as single scores, you calculate the mean by adding up all the scores, then dividing the total by the number of scores.
If the data is given in a frequency table then sum the scores multiplied each by their frequency before dividing by the total number of data points.
If the data is grouped, then first find the midpoint of each class interval, sum the midpoints multiplied by the frequency and then divide by the total of the frequency column.
Median
The median is the middle score in a data set when the scores are arranged in numerical order.
There are two ways you can find the median:
- Write the numbers in the data set in ascending order, then find the middle score by crossing out a number at each end until you are left with one in the middle.
- Calculate what score would be in the middle using the formula: $\text{middle term }=\frac{n+1}{2}$middle term =n+12, then count up in ascending order until you reach the score that is that term.
Note: If the data is grouped using class intervals you must add up the frequency column until you come to the interval where the middle score must lie. The interval will be called the median class.
Mode
The mode is the most frequently occurring score.
To find the mode, count which score you see most frequently in your data set. If the data is in a frequency table, the score with the highest frequency is the mode. If the data is grouped then the modal class will be the class interval with the highest frequency.
Worked examples
Example 1
A statistician has organised a set of data into the frequency table shown. Determine the mean, median and mode for the data.
| Score ($x$x) | Frequency ($f$f) | $fx$fx |
|---|---|---|
| $44$44 | $8$8 | $352$352 |
| $46$46 | $10$10 | $460$460 |
| $48$48 | $6$6 | $288$288 |
| $50$50 | $18$18 | $900$900 |
| $52$52 | $5$5 | $260$260 |
| Totals | $47$47 | $2260$2260 |
The mean is $\overline{x}=\frac{2260}{47}=48.01$x=226047=48.01
To find the median first work out which score it must be using the formula
$\text{Middle term }$Middle term $=$= $\frac{n+1}{2}$n+12
Think: There are 47 scores so the median score will be the value of score number $\frac{47+1}{2}=24$47+12=24
Do: Add the numbers downwards in the frequency column until you get to the 24th score. $8+10+6=24$8+10+6=24
Therefore the median score is $48$48.
To find the mode find the score with the highest frequency. The highest frequency is 18, therefore
the mode is $50$50.
Practice questions
Question 3
Consider the table below.
| Score | Frequency |
|---|---|
| $1$1 - $4$4 | $2$2 |
| $5$5 - $8$8 | $7$7 |
| $9$9 - $12$12 | $15$15 |
| $13$13 - $16$16 | $5$5 |
| $17$17 - $20$20 | $1$1 |
Use the midpoint of each class interval to determine an estimate for the mean of the following sample distribution. Round your answer to one decimal place.
Which is the modal group?
$1$1 - $4$4
A$17$17 - $20$20
B$13$13 - $16$16
C$5$5 - $8$8
D$9$9 - $12$12
E
Analysing univariate data: measures of spread
The range, interquartile range, variance and standard deviation are all measures of spread. They tell us about how spread out the scores are.
Range
The range is the difference between the highest score and the lowest score.
To calculate the range, you need to subtract the lowest score from the highest score.
Interquartile range
The interquartile range (IQR) gives a measure of spread of the middle $50%$50% of the data set.
The interquartile range often gives a better indication of the internal spread than the range does, as it is less affected by individual scores that are unusually high or low, which are the outliers.
Remember to make sure the data set is ordered before finding the quartiles or the median.
Subtract the first quartile from the third quartile. That is,
$\text{IQR }=Q_3-Q_1$IQR =Q3−Q1
Practice questions
Question 4
Answer the following, given this set of scores:
$33,38,50,12,33,48,41$33,38,50,12,33,48,41
Sort the scores in ascending order.
Find the number of scores.
Find the median.
Find the first quartile of the set of scores.
Find the third quartile of the set of scores.
Find the interquartile range.
Question 5
The column graph shows the number of pets that each student in a class owns.
Find the first quartile of the set of scores.
Find the third quartile of the set of scores.
Find the interquartile range.
Standard Deviation
Standard deviation is a measure of spread from the mean. It is a weighted average of the distance of each data point from the mean. A small standard deviation indicates that most scores are close to the mean, while a large standard deviation indicates that the scores are more spread out away from the mean value.
We can calculate the standard deviation for a population or a sample. In this course, we will be finding the population standard deviation.
The symbols used are:
| $\text{Population Standard Deviation}$Population Standard Deviation | $=$= | $\sigma$σ | (lowercase sigma) |
In statistics mode on a calculator, the following symbols might be used:
| $\text{Population Standard Deviation}$Population Standard Deviation | $=$= | $\sigma_n$σn |
When using the calculator to find the standard deviation, ensure settings are correct for the data given, this is particularly important when changing between data that is in a simple list to data that is in a frequency table.
Practice questions
Question 6
Find the population standard deviation of the following set of scores, to two decimal places, by using the statistics mode on the calculator:
$8,20,9,9,8,19,9,18,5,10$8,20,9,9,8,19,9,18,5,10
Question 7
The table shows the number of goals scored by a football team in each game of the year.
| Score ($x$x) | Frequency ($f$f) |
|---|---|
| $0$0 | $3$3 |
| $1$1 | $1$1 |
| $2$2 | $5$5 |
| $3$3 | $1$1 |
| $4$4 | $5$5 |
| $5$5 | $5$5 |
In how many games were $0$0 goals scored?
Determine the median number of goals scored. Leave your answer to one decimal place if necessary.
Calculate the mean number of goals scored each game. Leave your answer to two decimal places if necessary.
Use your calculator to find the population standard deviation. Leave your answer to two decimal places if necessary.
Question 8
Fill in the table and answer the questions below.
Complete the table given below.
Class Class Centre Frequency $fx$fx $1-9$1−9 $\editable{}$ $8$8 $\editable{}$ $10-18$10−18 $\editable{}$ $6$6 $\editable{}$ $19-27$19−27 $\editable{}$ $4$4 $\editable{}$ $28-36$28−36 $\editable{}$ $6$6 $\editable{}$ $37-45$37−45 $\editable{}$ $8$8 $\editable{}$ Totals $\editable{}$ $\editable{}$ Use the class centres to estimate the mean of the data set, correct to two decimal places.
Use the class centres to estimate the population standard deviation, correct to two decimal places.
If we used the original ungrouped data to calculate standard deviation, do you expect that the ungrouped data would have a higher or lower standard deviation?
Higher standard deviation
ALower standard deviation
B
Analysing univariate data: outliers
An outlier is an event that is very different from the norm and results in a score that is far away from the rest of the scores.
A data point is classified as an outlier if it lies more than $1.5$1.5 interquartile ranges above the upper quartile or more than $1.5$1.5 interquartile ranges below the lower quartile.
Below $Q_1-1.5\times\text{IQR}$Q1−1.5×IQR
OR
More than $Q_3+1.5\times\text{IQR}$Q3+1.5×IQR
Analysing univariate data: box plots
A five number summary consists of the:
- Minimum value
- Lower quartile (Q1)
- Median
- Upper quartile (Q3)
- Maximum value
Using the five number summary we can construct a box and whisker plot.

The two vertical edges of the box show the quartiles of the data range. The left hand side of the box is the lower quartile (Q1) and the right hand side of the box is the upper quartile (Q3). The vertical line inside the box shows the median (the middle score) of the data.
Then there are two lines that extend from the box outwards. The endpoint of the left line is at the minimum score, while the endpoint of the right line is at the maximum score.
Practice questions
QUESTION 9
VO2 Max is a measure of how efficiently your body uses oxygen during exercise. The more physically fit you are, the higher your VO2 Max. Here are some people’s results when their VO2 Max was measured.
$46,27,32,46,30,25,41,24,26,29,21,21,26,47,21,30,41,26,28,26,76$46,27,32,46,30,25,41,24,26,29,21,21,26,47,21,30,41,26,28,26,76
Sort the values into ascending order.
Determine the median VO2 Max.
Determine the upper quartile value. Leave your answer as a decimal if necessary.
Determine the lower quartile value. Leave your answer as a decimal if necessary.
Calculate $1.5\times IQR$1.5×IQR, where IQR is the interquartile range. Leave your answer as a decimal if necessary.
An outlier is a score that is more than $1.5\times IQR$1.5×IQR above or below the Upper Quartile or Lower Quartile respectively. State the outlier.
Here is a box and whisker plot for the data.

An average untrained healthy person has a VO2 Max between $30$30 and $40$40. The majority of this group of people are likely to:
do moderate amounts of exercise
Abe professional athletes
Bdo none to moderate amounts of exercise
C
Question 10
Consider the following set of data:
$1$1 $6$6 $4$4 $9$9 $8$8 $5$5 $2$2
Complete the five-number summary for this data set.
Minimum $\editable{}$ Lower quartile $\editable{}$ Median $\editable{}$ Upper quartile $\editable{}$ Maximum $\editable{}$ Would the value $15$15 be considered an outlier?
Yes
ANo
B
Analysing univariate data: compare data sets and comment on the shape of data
Measures of central tendency and measure of spread can be very powerful in comparing and contrasting two different data sets.
We also can benefit from examining the shape of the distribution of two sets of data when comparing them.
Analysing univariate data: symmetry
Data may be described as symmetrical or asymmetrical (skew).
There are many cases where the data tends to be around a central value with no bias left or right. In such a case, roughly $50%$50% of scores will be above the mean and $50%$50% of scores will be below the mean.
The normal distribution is the most common example of symmetrical data. The normal distribution looks like this:
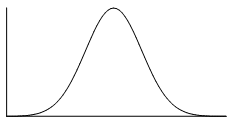
The picture below shows how the normal distribution can occur on a histogram. The dark line shows the nice, symmetrical polygon that can be drawn over the histogram.

In the distribution above, the middle represents the mean, the median and the mode - all these measures of central tendency are equal for this distribution since it is symmetrical.
Positive skew
A data set that has positive skew (sometimes called a 'right skew') has a long tail of values above the peak of the graph, such that more than half of the scores are above the peak. This means the mean is greater than the median, which is greater than the mode.
MODE < MEDIAN < MEAN
A positively skewed graph looks something like this.
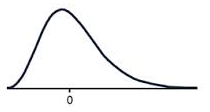
Notice that there are more scores above the peak than below the peak.
Negative skew
A data set that has negative skew (sometimes called a 'left skew') has a long tail of values below the peak of the graph, such that more than half of the scores are below the peak. This means the mode is greater than the median, which is greater than the mean.
MEAN < MEDIAN < MODE
A negatively skewed graph looks something like this.
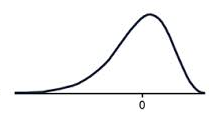
Notice that there are more scores below the peak than above the peak.
Practice questions
Question 11
State whether the scores in each histogram are positively skewed, negatively skewed or symmetrical (approximately).
A histogram that represents the distribution of scores. The x-axis enumerates discrete scores as individual points, while the y-axis corresponds to the frequency of each score interval. Each bar on the histogram corresponds to one of these distinct scores, with the bar's height reflecting the count or frequency of occurrences for that particular score. Most of the scores are relatively high. Positively skewed
ASymmetrical
BNegatively skewed
CA histogram that represents the distribution of scores. The x-axis enumerates discrete scores as individual points, while the y-axis corresponds to the frequency of each score interval. Each bar on the histogram corresponds to one of these distinct scores, with the bar's height reflecting the count or frequency of occurrences for that particular score. Approximately, as the score goes higher, the frequency goes lower. Positively skewed
ANegatively skewed
BSymmetrical
CA histogram that represents the distribution of scores. The x-axis enumerates discrete scores as individual points, while the y-axis corresponds to the frequency of each score interval. Each bar on the histogram corresponds to one of these distinct scores, with the bar's height reflecting the count or frequency of occurrences for that particular score. The scores have its peak approximately in the middle. Negatively skewed
ASymmetrical
BPositively skewed
C
Question 12
The beaks of two groups of bird are measured, in mm, to determine whether they might be of the same species.
| Group 1 | $33$33 | $39$39 | $31$31 | $27$27 | $22$22 | $37$37 | $30$30 | $24$24 | $24$24 | $28$28 |
|---|---|---|---|---|---|---|---|---|---|---|
| Group 2 | $29$29 | $44$44 | $45$45 | $34$34 | $31$31 | $44$44 | $44$44 | $33$33 | $37$37 | $34$34 |
Calculate the range for Group 1.
Calculate the range for Group 2.
Calculate the mean for Group 1. Give your answer as a decimal.
Calculate the mean for Group 2. Give your answer as a decimal.
Choose the most appropriate statement that describes the set of data.
Although the ranges are similar, the mean values are significantly different indicating that these two groups of birds are of the same species.
AAlthough the ranges are similar, the mean values are significantly different indicating that these two groups of birds are not of the same species.
BAlthough the mean values are similar, the ranges are significantly different indicating that these two groups of birds are not of the same species.
CAlthough the mean values are similar, the ranges are significantly different indicating that these two groups of birds are of the same species.
D
Question 13
The box plots drawn below show the number of repetitions of a $70$70 kg bar that two weightlifters can lift. They both record their repetitions over $30$30 days.

Which weightlifter has the more consistent results?
Weightlifter A.
AWeightlifter B.
BWhat statistical evidence supports your answer?
The mean.
AThe range.
BThe mode.
CThe graph is positively skewed.
DWhich statistic is the same for each weightlifter?
The median.
AThe mean.
BThe mode.
CWhich weightlifter can do the most repetitions of $70$70 kg?
Weightlifter A.
AWeightlifter B.
B